前言
Zookeeper作为微服务分布式协调中间件,了解它的原理以及日常开发中的注意事项和可能会出现的问题是有必要的。
前置知识:ZAB协议
ZAB:Zookeeper Atomic Broadcast(ZAB)崩坏恢复和原子广播协议
1)崩坏恢复:在master节点宕机情况下,其他集群节点会重新选举master节点,快速领导者选举机制:选举规则会参照最大的分代年龄epoch>最大的事务zxid>server id来进行选举,选举过程就是将自己节点投票信息发给其他集群节点,投票信息附带zxid和serverid,判断是否超过一半的投票选同一个节点,那么这个节点就会选举为master。
2)选举完后,就会进行数据同步,将master节点数据同步到slave中,此时对外服务不可用。
3)原子广播:ZAB协议保证消息的一致性和有序性
一致性:leader发送propasal事务请求(包含zxid),master判断过半机制ack,就认为事务可以提交了,master会提交事务,然后广播提交事务消息,从节点开始提交本事务。一半ack机制,可以看zookeeper是CP,但是不是强一致性;从节点接收propasal后,会将事务写入磁盘。
有序性:zxid事务id保证全局有序性,每一个slave服务器维持一个FIFO队列,维持局部有序性。
Zookeeper脑裂
Zookeeper脑裂都是出现在集群环境中的。指的是一个集群环境中出现了多个master节点,导致严重数据同步和写入问题,数据不一致等等,如果这种情况出现在线上分布式环境下,会导致服务不可用。
出现原因
可能就是网络环境有问题导致节点之间断开,或者节点假死等等,导致一部分slave节点会重新进入崩坏恢复模式,重新选举新的master节点,然后对外提供事务服务。由于心跳超时(网络原因导致的)认为旧的master死了,但其实旧的master还存活着。
如何解决脑裂
过半机制,如果集群中某个节点的投票数量大于集群有效节点的一半,就会选出master。这里拿出关键代码:
// 验证是否符合过半机制,如果符合就会选举新的master节点
public boolean containsQuorum(Set<Long> set){
// half是在构造方法里赋值的
// n表示集群中zkServer的个数(准确的说是参与者的个数,参与者不包括观察者节点)
half = n/2;
// set.size()表示某台zkServer获得的票数
return (set.size() > half);
}
笔者介绍几种情况,来说明一下几种脑裂的场景
-
比如集群中有6个节点,一个master和5个slave,分两个机房,每个机房分别三台,发生了机房不可通信的情况,如下图:
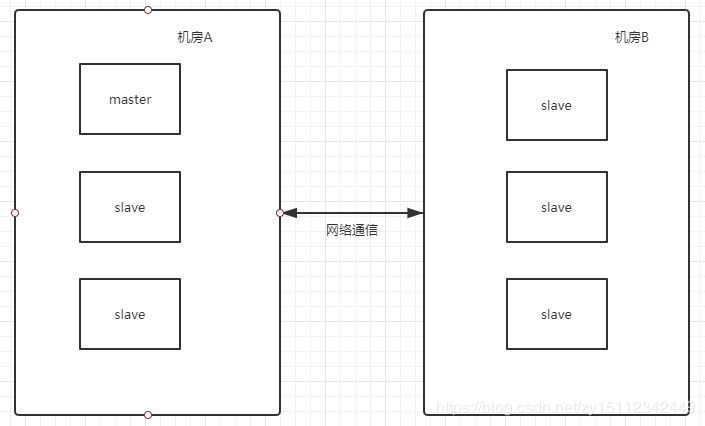
然后机房B就会产生新的master,如图
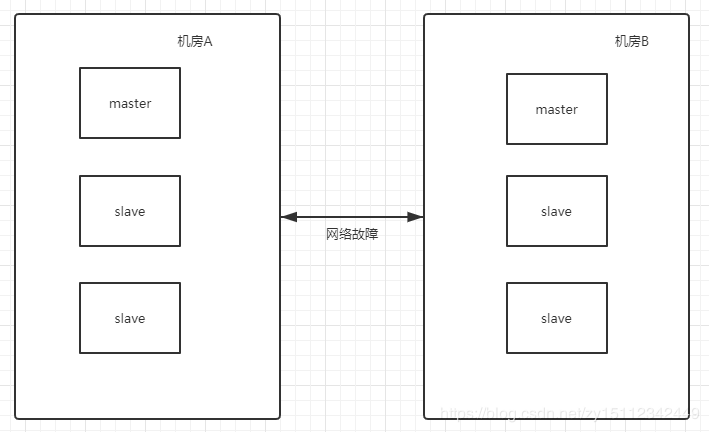
这个时候Zookeeper为了防止这样的情况发生,利用了过半机制的这个特性。
上图中,机房B节点为3 小于集群数量的一半,所以,最终上面图中机房B是不会选举出新的master节点的。 -
我们再来看一种情况:比如集群中有5个节点,一个master和4个slave,分两个机房,如下图:
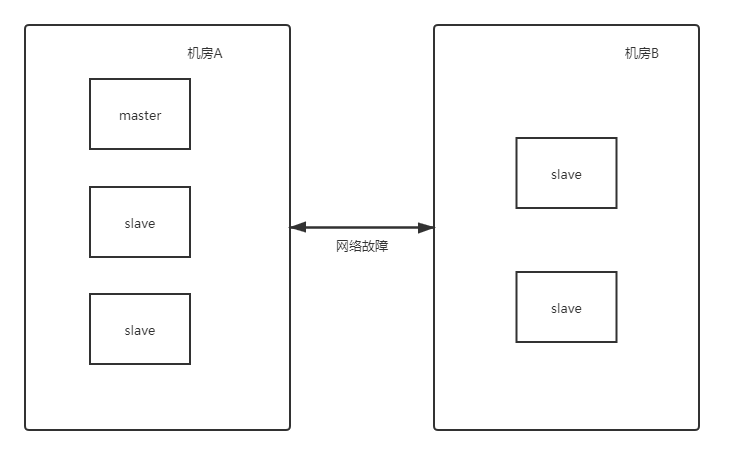
如果发生了机房不能通信的情况,那么机房B因为节点是2个,没有超过一半,就不会产生出新的master节点了。 -
再来看最后一种情况,比如集群中有5个节点,一个master和4个slave,分两个机房,不同的是master节点在机房B,如下图:
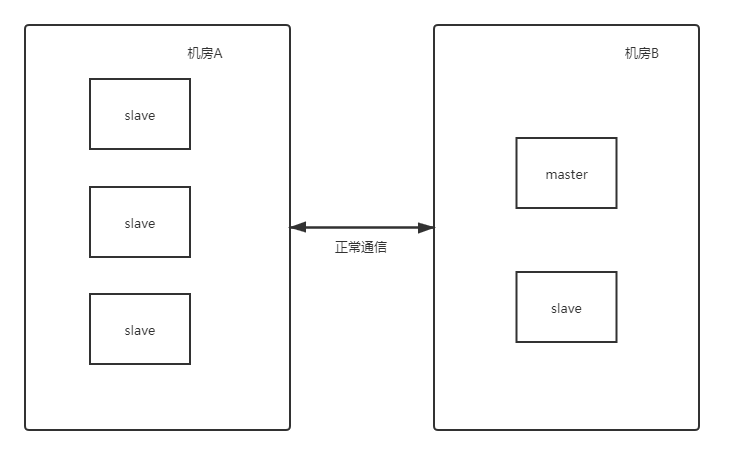
如果发生了机房不能通信的情况,那么机房A节点是3个,超过了一半,就会进入崩坏恢复模式产生新的master节点,那么此时集群中就会出现两个master节点了。如下图所示
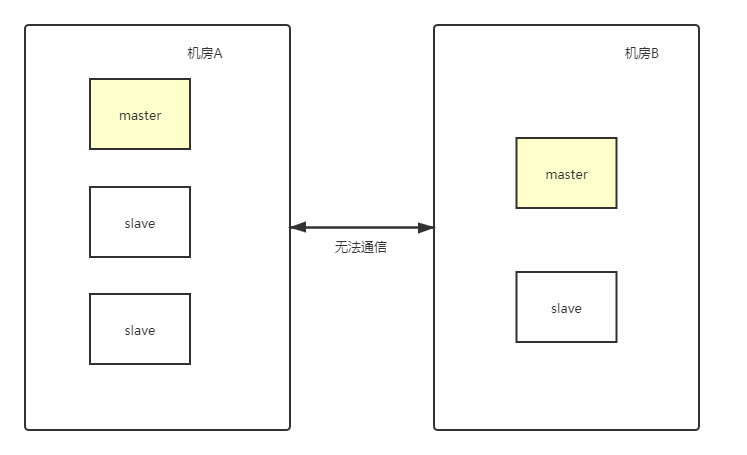
那么遇到这种情况Zookeeper是如何处理的?答:旧的leader所有的写请求同步到其他followers节点是会被拒绝的。因为每当新leader产生时,会生成一个epoch,这个epoch是递增的,followers如果确认了新的leader存在,知道其epoch,就会拒绝epoch小于现任leader epoch的所有请求。这个时候旧的master进入恢复模式进行数据同步。
所以按照上面的情况,机房A的所有followers节点正常通信,机房B的所有节点重新进入恢复模式进行数据同步。
总结:通过Quorums机制来防止脑裂,当leader挂掉之后,可以重新选举出新的leader节点使整个集群达成一致;当出现假死现象时,通过epoch大小来拒绝旧的leader发起的请求,当出现这种情况,旧的leader 进入恢复模式进行数据同步。
引出奇数节点
知晓以上场景后,我们知道,2台机器也能选举出master,只不过只要有1个死了zookeeper就不能用了,因为1没有过半。所以2个zookeeper的死亡容忍度为0。同理,要是有3个zookeeper,一个死了,还剩下2个正常的,过半了,所以3个zookeeper的容忍度为1。如果按照这样的机制推理,那么得出2->0;3->1;4->1;5->2;6->2 左边是数量,右边是容忍度,所以2n和2n-1的容忍度是一样的,所以可以得出,集群是奇数个能够节省资源。
总结
以上,笔者总结了ZAB协议,到Zookeeper防止脑裂的场景以及如何处理,以及结合例子,Zookeeper集群在奇数节点下的作用。
参考
- ZooKeeper集群的脑裂问题——https://www.cnblogs.com/shoufeng/p/10591526.html