一、背景
随着业务模式的扩大,多个平台下用户数量不断扩大。并且因为业务需要,需要合并两个业务系统的用户中心,因为需要对接三方系统,所以要求用户的ID标识不能体现出系统的用户量。
技术团队考虑到这种场景以及后续用户的扩大,需要一个方案去解决在分布式环境下ID递增的问题,系统自己的ID递增算法也需要做改变。
二、业界比较流行的分布式ID解决方案
技术团队首先考察业界比较流行的做法,总结不同方案优缺点,然后根据自己的业务来选择更合适的方案。
2.1 数据库分批ID分发
数据库分批ID原理主要是利用分批思想以及乐观锁来解决,目前淘宝中间件TDDL其中的主键分配就是用了这个方案。该方案具体是这样做的:
- 数据库表维护一条数据,记录当前分配ID号以及偏移数量等数据
- 编写服务,利用乐观锁去CAS更新数据,更新成功就说明拿到了一批ID号,失败的话进行重试,设置一定的重试次数
- 放入本地缓存或者redis做扣减,如果用完就重复步骤2
具体的的表可以是类似这样的:
| 字段 | 描述 |
|---|---|
| id | 自增ID,没有业务意义 |
| current_num | 当前已经分配的ID最大值 |
| limit | 一次分配多少个ID |
| version | 版本号,CAS更新用 |
| create_time | 记录创建时间 |
| update_time | 记录更新时间 |
比如,limit=1000,一次分配1000个ID,没分配之前current_num = 0,第一次current_num = 1000,第二次依次类推。
当然,上述的方案也有缺点:
- 一条数据,如果有大量流程去更新,要竞争获取行锁,会有性能问题,(可以参考行锁的利弊,丁奇——秒杀场景下MySQL的低效)
- 强依赖DB,如果当前数据库宕机,导致分布式ID分发服务就会出现问题
- 如果在主从数据库场景下,需要考虑到主从的延迟性导致分配ID的不一致性
所以为了解决上面的问题,笔者参考concurrentHashMap分段锁的思想,将一条记录分段为多个,同时为了避免DB单点可用性,可以将不同的记录分布在不同的数据库上面。
具体的表可以是类似这样的:
| 字段 | 描述 |
|---|---|
| id | 自增ID,没有业务意义 |
| current_num | 当前已经分配的ID最大值 |
| limit | 一次分配多少个ID |
| offset | 前后分配的ID间隔数 |
| initial_id | 初始自增的ID |
| version | 版本号,CAS更新用 |
| create_time | 记录创建时间 |
| update_time | 记录更新时间 |
新增offset偏移和initial_id字段,offset代表数据库表记录前后分配间隔数量,initial_id代表开始初始的值。
举个例子,现在将记录分为10条,分布在不同数据库上,那么offset就是10000,limit就是1000,第一条记录第一次开始配合获取0-1000,第二次分配获取10000-11000,依次类推。
这里需要考虑一个问题,就是如果请求ID分发的服务的流量怎么路由到具体的记录呢?如果流量全部都请求到第一条记录上了,就会导致请求不均。
这个问题很简单,有一定开发经验的读者自然可以联想到用一致性hash去路由,具体路由的key可以根据业务去定,比如用户手机号。(具体一致性hash路由如何实现,可以参考利用treeMap实现)
以上方案算是解决性能问题,但是还有比较致命的问题,就是无法横向扩展。就比如说现在有10台机器不同数据库,每一个数据库一条记录。假如现在有新的机器10台机器想要加入分配的话,那么就要修改offset和initial_id,所以在不停机实现的话,可能无法实现(目前笔者没有想到方法解决,如果读者有idea可以欢迎和我讨论)。这里笔者提供一种方法去解决:
提前预先分配100条记录,每一条记录一批次获取100个ID,offset设置为10000,当前10台机器每一台有10条记录,后续有新机器的话直接将记录不停机转移到新机器就可以了。
2.2 Redis序列化分发
Redis来生成ID,这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。目前单台redis的qps能够达到5W,所以一定程度上能够解决性能问题。具体实现笔者这里就不阐述了。
当然用这个方案也有缺点:
- 依赖redis,如果业务中没有就要依赖这个中间件
- 生成的ID是单调递增的,容易暴露系统的用户数
2.3 SnowFlake雪花算法
以上2.1 2.2方案都能解决性能问题,但是产生的ID,是连续的,容易暴露自己系统中用户的数量。所以有些系统会要求要趋势递增,而且要保持信息安全。目前雪花算法就能解决这个问题。
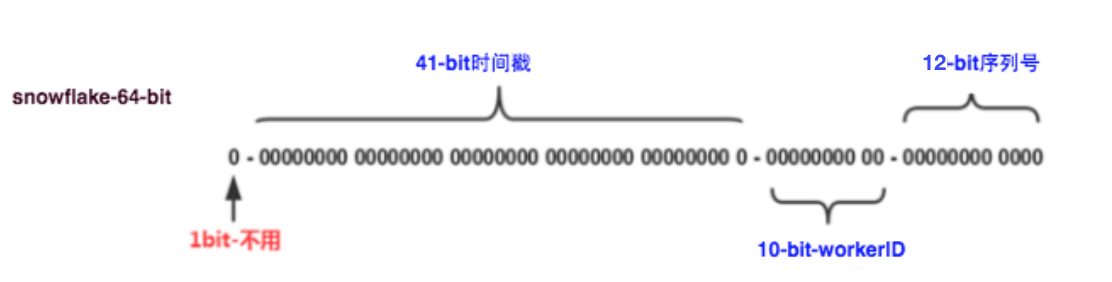
其中原理就是:给一个64位的二进制数字,其中
- 第1位置为0。
- 第2-42位是相对时间戳,通过当前时间戳减去一个固定的历史时间戳生成。
- 第43-52位是机器号workerID,每个Server的机器ID不同。
- 第53-64位是自增ID。
这个方案也有缺点:
- 实现比较复杂,考验开发人员
- 需要独立部署实现
- 强依赖时钟,时钟回拨会有重复的ID
三、当前方案是如何做的
参考上述方案后,技术团队考虑到未来业务的增加,流量的增长以及后续的扩展,准备利用方案三去实现。其中具体实现可以参考笔者GitHub的实现:分布式ID SnowFlake实现
当然使用方案三也会有缺陷,比如会发生时钟回拨问题,以及分布式ID分发服务强依赖zookeeper。
3.1 时钟回拨
发生时钟回拨的原因是,如果分发服务正在生成ID的过程中,系统时间因为不可抗拒的因素或者人为因素导致时间倒流了,会导致可能会有重复的ID生成,作为分布式ID分发这个是不准发生的。所以如果发生时钟回拨那么就抛出异常,实现如下
long timestamp = System.currentTimeMillis();
// 如果当前时间戳小于上次分发的时间戳
if (timestamp < lastTimestamp) {
long offset = lastTimestamp - timestamp;
if (offset <= 5) {
// 如果时间戳间隔小于5,那么进行等待,等待窗口时间,然后再进行重试
try {
wait(offset << 1);
timestamp = System.currentTimeMillis();
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format("lastTimestamp %s is after reference time %s", lastTimestamp, timestamp));
}
} catch (InterruptedException e) {
logger.error("wait interrupted");
throw new RuntimeException(String.format("lastTimestamp %s is after reference time %s", lastTimestamp, timestamp));
}
} else {
// 如果相差过大,直接抛出异常
throw new RuntimeException(String.format("lastTimestamp %s is after reference time %s", lastTimestamp, timestamp));
}
}
// 如果等于,表明同一时刻
if (lastTimestamp == timestamp) {
// 如果小于计数器最大值就,增加
if (this.counter < MAX_SEQUENCE) {
this.counter++;
} else {
// 表明同一时刻,同一机器下,的所有计数器都用完了
throw new RuntimeException("Sequence exhausted at " + this.counter);
}
} else {
//如果是新的ms开始
counter = 0L;
}
// 记录这一次时间戳,用作下一次比较
lastTimestamp = timestamp;
// 后续的生成ID逻辑
3.2 强依赖zookeeper
以上能解决时钟回拨的问题,但是强依赖zookeeper来生成分布式环境下的当前机器的ID。笔者参考dubbo的设计思想,当ID分发服务通过ID+端口注册到zookeeper的递增持久节点后,返回的节点直接存储再本地文件中,实现高可用,如下
/**
* 高可用,防止zookeeper挂了,本地本机生效
* 写入本地文件的时机:当前机器获取zookeeper的持久节点后
*/
private void writeWorkerId2Local(int workerId){
String path = WORKERID_PATH + File.separator + applicationName + File.separator + "workerId.properties";
File file = new File(path);
if(file.exists() && file.isFile()){
try {
FileUtils.writeStringToFile(file, "workerId=" + workerId, false);
}catch (Exception e){
logger.error("e:", e);
}
}else {
boolean mkdirs = file.getParentFile().mkdirs();
if(mkdirs){
try {
if (file.createNewFile()) {
FileUtils.writeStringToFile(file, "workerId=" + workerId, false);
logger.info("local file cache workerID is {}", workerId);
}
}catch (Exception e){
logger.error("e:", e);
}
}
}
}
四、采用分布式ID上线后产生的BUG
4.0 问题分析
当上线分布式ID分发服务后,观察日志,出现大量的报错,如下:
io.lettuce.core.RedisCommandExecutionException: ERR bit offset is not an integer or out of range
at io.lettuce.core.ExceptionFactory.createExecutionException(ExceptionFactory.java:135) ~[lettuce-core-5.2.1.RELEASE.jar:5.2.1.RELEASE]
at io.lettuce.core.ExceptionFactory.createExecutionException(ExceptionFactory.java:108) ~[lettuce-core-5.2.1.RELEASE.jar:5.2.1.RELEASE]
at io.lettuce.core.protocol.AsyncCommand.completeResult(AsyncCommand.java:120) ~[lettuce-core-5.2.1.RELEASE.jar:5.2.1.RELEASE]
at io.lettuce.core.protocol.AsyncCommand.complete(AsyncCommand.java:111) ~[lettuce-core-5.2.1.RELEASE.jar:5.2.1.RELEASE]
at io.lettuce.core.protocol.CommandHandler.complete(CommandHandler.java:654) ~[lettuce-core-5.2.1.RELEASE.jar:5.2.1.RELEASE]
at io.lettuce.core.protocol.CommandHandler.decode(CommandHandler.java:614) ~[lettuce-core-5.2.1.RELEASE.jar:5.2.1.RELEASE]
…………
乍看是redis的抛出来的错误,和这次分布式ID改造没有什么关系,但是仔细静下来想一想,这次ID改造是从原来的数据库自增改造的,数据库自增数据主键很小是int类型,然后用了64位二进制数据当作ID后,导致redis中用户的数据存不下去,然后笔者就按照这个思路去发掘问题。
笔者从业务抛出的堆栈中发现,这个错误是在判断用户是否是新用户服务方法中抛出的,而判断是新用户的逻辑就是,利用redis的bitmap来解决的:getbit new_user_key userId,其中 userId为用户ID,如果用户发生了交易信息,就会执行:setbit new_user_key userId 1 这个命令。 为什么要用bitmap解决呢,主要是因为如果从交易记录表查询某个用户是否交易信息来判断是新用户的话就会非常耗时,所以只要是发生了交易信息就设置bitmap就可以了。
那为什么会抛出out of range这个错误呢,我们知道bitmap底层其实就是String类型,而String类型的最大长度为512M,官网截图:
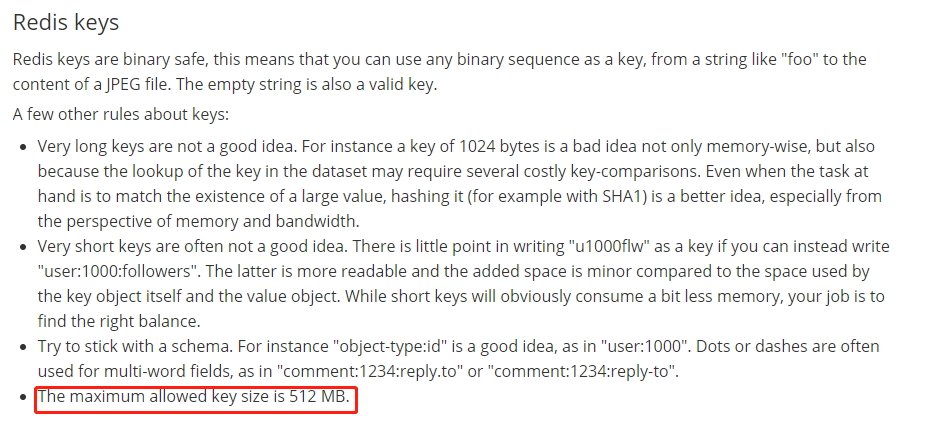
所以如果offset超过512M这个范围那么就会抛出异常,512M = 2^9 * 2^12 * 2^12 * 2^3 = 2^32 bit,也就是支持Integer类型的最大值,而我们这次分布式ID服务ID是64位的,支持2^64 bit,所以如果offset也就是userId大于2^32的话就会抛出out of range异常了。
4.1 问题解决
找到了问题,也就好去做优化了,这里笔者提供几个方法作为参考
- 在数据库用户表或者用户扩展表中增加一个字段,如果发生了交易,那么将字段标记为老用户
- 把用户ID放入redis集合set中,利用SMISMEMBER命令判断当前用户是否在集合内,当然这个会有性能问题,其方法时间复杂度位O(N),官方截图:

五、总结
笔者从分布式ID选型出发,介绍了几种业界几种比较常用的生成方法,并且介绍了其优缺点,然后结合实际业务出发,选择合适的方案。然后介绍了使用SnowFlake算法导致的业务问题,以及分析最后提供解方法。从这次踩坑的经历来说,我们要懂技术体系,并且还要非常熟悉业务,最大程度避免功能之间的相互的影响导致的bug。
六、参考
- 美团分布式算法ID几种实现方式——https://tech.meituan.com/2017/04/21/mt-leaf.html
- SnowFlake算法——https://github.com/twitter-archive/snowflake