前言
在对MySQL开发中,联合索引是很常见的一种MySQL优化方式,本文解释了联合索引的存储以及查找过程,可以了解一下底层的原理以及加深对MySQL联合索引的理解。
Innodb B+树
先看一下Innodb B+树的主键索引和辅助索引。这里直接拿张洋大神的图:
- 聚簇索引:
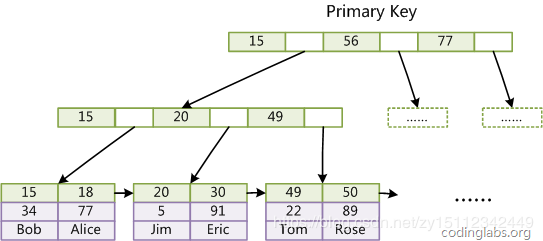
- 辅助非聚簇索引:
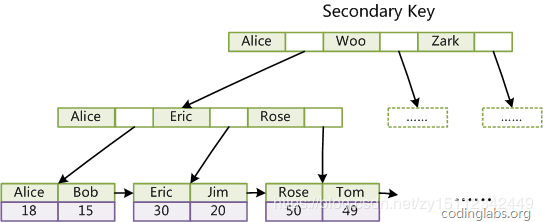
结构:当一个表T(id,name,age,sex,high)建一个普通索引 KEY(name),name的索引结果就和上面辅助非聚簇索引结构一样。
查询:当有一个select id,name,age from T where name = "" 辅助索引会根据name在B+树上进行二叉树查找,找出叶子节点数据后发现没有age这个数据,就会进行回表操作到主键聚簇索引去查找,拿到聚簇索引叶子节点的age数据。
联合索引存储以及寻址
-
索引结构:我们知道上述回表过程也会消耗性能,相当于多查一次,所以系统可以根据业务情况加上一个组合索引,当然并不是一直加组合索引就可以了,因为要考虑到索引存储空间的问题。例如给上述加上一个组合索引 KEY(name,age,sex)【 KEY(col1,col2,col3)】。那么这个组合索引的B+树非叶子节点数据结构和上述辅助非聚簇索引图一样,但是叶子节点是这样的:
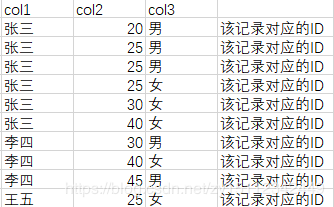
叶子节点存储col1,col2,col3这三列数据以及加上ID这一列数据。 -
寻址过程:
例如语句:select * from T where name = "张三" and age=25,先根据name字段从辅助聚簇索引定位到哪一个叶子节点数据中,然后根据age节点在上述表格的前6行中,寻找age= 25的数据,然后找出所有符合的数据以及其对应的ID,然后根据ID来进行回表操作查询。这里返回了三条数据,就回了三次表。
上述回表过程中,笔者引入一个索引下推的一个功能,索引下推是MySQL在5.6版本后引入的一个查询优化。就拿上述的例子,在没有优化之前,据name字段查询“张三”后,会拿到6条结果,回表6次,然后从主键索引拿到6条数据后,根据age字段筛选数据;优化之后,先再辅助索引上面根据name字段和age字段筛选符合数据,也就是ID,然后再回表,这里回表了三次。 -
组合索引注意事项
当然,联合索引的最重要的是注意联合索引的使用问题,要遵循最左匹配原则,才可以优化到整个SQL了。
总结
以上,总结了MySQL的索引的基本原理,以及联合索引的存储和寻址过程,并且引入索引下推概念,还有使用联合索引的注意事项。
参考
- MySQL索引背后的数据结构及算法原理——http://blog.codinglabs.org/articles/theory-of-mysql-index.html。