前言
笔者先从linkedHashMap源码中借鉴插入顺序访问的代码,然后然后自己实现了一个LRU
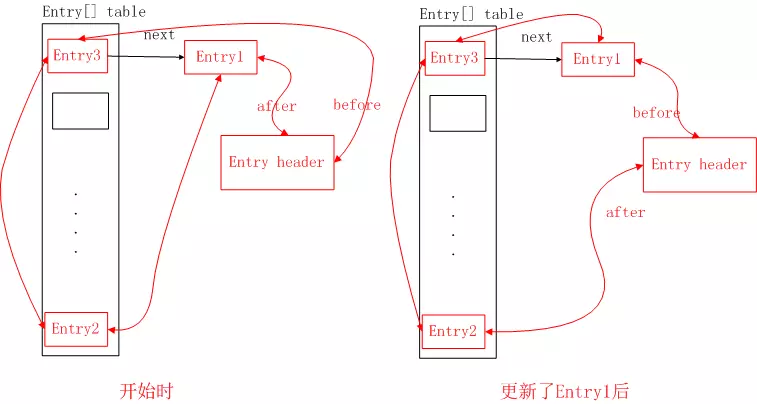
linkedHashMap底层的数据结构
linkedHashMap底层结构(顺序访问):
- 1、linkedHashMap维护了每个node的双向链表,初始化时候维护了空的entry header头,新加入的节点放到entry的头部header的next
- 2、put还是get都会进行重排序,get entry1 还是put entry1都会先把Entry1从双向链表中删除,然后再把Entry1加入到双向链表的表尾。
- 3、遍历访问的时候,会访问header的下一个next节点,这就形成了顺序访问
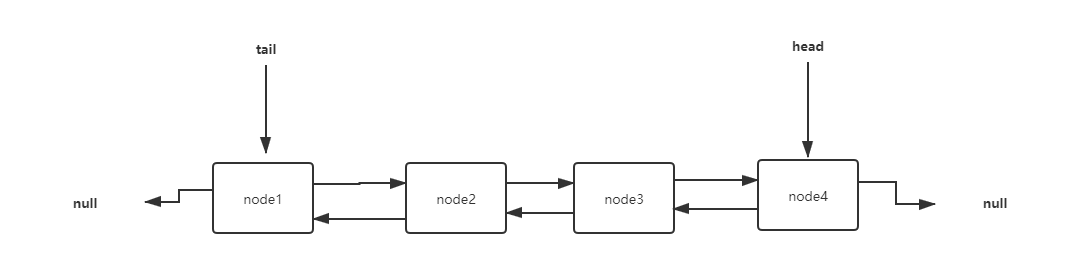
链表实现
实现思路:
- 1、数据是直接利用 HashMap 来存放的。
- 2、内部使用了一个双向链表来存放数据,所以有一个头结点 header,以及尾结点 tailer。
- 3、每次写入头结点,删除尾结点时都是依赖于 header tailer
import com.google.common.collect.Maps;
import java.util.Map;
/**
* 线程不安全,同步机制自行控制。
*/
public class LRUCacheV2 {
/**
* 缓存map
*/
private final Map<String, Node> cacheMap;
/**
* 头指针
*/
private Node head;
/**
* 尾指针
*/
private Node tail;
/**
* 容量
*/
private final int cacheSize;
/**
* 当前容量
*/
private int currentCacheSize;
LRUCacheV2(int capacity){
cacheMap = Maps.newHashMapWithExpectedSize(capacity);
cacheSize = capacity;
currentCacheSize = 0;
}
public Object get(String key){
Node node = cacheMap.get(key);
if(node != null){
// 移动到头指针
move2head(node);
return node.getData();
}
return null;
}
public void remove(String key){
Node node = cacheMap.get(key);
if(node != null){
Node pre = node.getPre();
Node next = node.getNext();
if(pre != null){
pre.setNext(next);
}
if(next != null){
next.setPre(pre);
}
// 如果删除刚好是头节点或者尾节点,也要移动指针
if(node.getKey().equals(head.getKey())){
head = pre;
}
if(node.getKey().equals(tail.getKey())){
tail = next;
}
cacheMap.remove(key);
}
}
public void put(String key, Object value){
Node node = cacheMap.get(key);
if(node != null){
// 存在节点的话,就覆盖,并且放到头
node.setData(value);
move2head(node);
cacheMap.put(key, node);
}else {
// 不存在节点,构造并且放到头
if(currentCacheSize == cacheSize){
// 删除尾node
String delKey = tail.getKey();
cacheMap.remove(delKey);
// 尾指针移动
Node next = tail.getNext();
if(next != null){
next.setPre(null);
}
tail.setNext(null);
tail = next;
}else{
currentCacheSize++;
}
node = new Node();
node.setData(value);
node.setKey(key);
// 头指针移动
move2head(node);
}
cacheMap.put(key, node);
}
/**
* 节点移到头
*/
private void move2head(Node node){
if(head == null){
// 初始化head 和 tail
head = node;
head.setNext(null);
head.setPre(null);
tail = node;
}else {
// 如果是相同的Key,啥都不用动,node就是最新的头
if(node.getKey().equals(head.getKey())){
return;
}
// 截取node
Node pre = node.getPre();
Node next = node.getNext();
if(pre != null){
pre.setNext(next);
}
if(next != null){
next.setPre(pre);
}
// 如果要截取的节点是尾节点,那么尾节点指针也要向前移动
if(node.getKey().equals(tail.getKey())){
tail = next;
}
// 放在头前面
head.setNext(node);
node.setPre(head);
// node下个指针指向null
node.setNext(null);
head = node;
}
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder() ;
Node node = head;
while (node != null){
sb.append(node.getKey()).append(":")
.append(node.getData())
.append("-->") ;
node = node.getPre();
}
return sb.toString();
}
public static void main(String[] args) {
LRUCacheV2 lruCacheV2 = new LRUCacheV2(4);
lruCacheV2.put("1","1");
lruCacheV2.put("2","2");
lruCacheV2.put("3","3");
lruCacheV2.put("4","4");
lruCacheV2.put("5","5");
//lruCacheV2.get("2");
//lruCacheV2.put("2","22");
lruCacheV2.remove("5");
System.out.println(lruCacheV2.toString());
}
}
链表实现V2
2021.3.15更新
上述的链表有点复杂,没有考虑到利用map的size,没有利用好头尾节点双向特性,笔者重新实现了下,参考leetcode146题
实现的几个要点
- 构造函数中要构造好头尾节点,形成指针闭环,为后续的增删移做好准备
- 删除节点的时候,可以根据map的value也就是Node的key,来删除map中的数据,也就是说,可以根据map的key来删除数据,也可以根据map的value中的key来删除数据
package com.zyblue.fastim.common.algorithm.distribute;
import java.util.HashMap;
import java.util.Map;
/**
* @author will
* @date 2021/3/15 10:18
*/
public class LRUCacheV3<K, V>{
public static class Node<K,V>{
public K key;
public V value;
public Node<K,V> pre;
public Node<K,V> next;
public Node(){}
public Node(K key, V value) {
this.key = key;
this.value = value;
}
}
/**
* map这样设计的原因是
* 1、
*/
private Map<K, Node<K,V>> map = new HashMap<>();
private int capacity;
private Node<K,V> head;
private Node<K,V> tail;
public LRUCacheV3(int capacity){
this.capacity = capacity;
this.head = new Node<>();
this.tail = new Node<>();
head.pre = tail;
tail.next = head;
}
private void remove2Head(Node<K,V> node){
Node<K, V> pre = node.pre;
Node<K, V> next = node.next;
pre.next = next;
next.pre = pre;
add2Head(node);
}
private void removeTail(){
Node<K, V> next = tail.next.next;
tail.next = next;
next.pre = tail;
}
private void add2Head(Node<K,V> node){
Node<K, V> pre = head.pre;
pre.next = node;
node.next = head;
node.pre = pre;
head.pre = node;
}
public V get(K key){
Node<K,V> node = map.get(key);
if(node == null){
return null;
}
remove2Head(node);
return node.value;
}
public void put(K key, V value){
Node<K,V> node = map.get(key);
if(node == null){
// 利用map的size
if(map.size() >= capacity){
// 去除尾部节点
removeTail();
// 删除map的node
map.remove(tail.next.key);
}
Node<K,V> nodeAdd = new Node<>(key, value);
add2Head(nodeAdd);
map.put(key, nodeAdd);
}else {
node.value = value;
remove2Head(node);
}
}
}
参考:
1、https://www.iteye.com/blog/gogole-692103
2、https://crossoverjie.top/2018/04/07/algorithm/LRU-cache/