背景
在目前的SaaS系统中,业务开发者需要重点关注的一个问题就是数据隔离问题,这个是做SaaS系统必须要考虑的点,多租户数据隔离是每个SaaS系统都要遇到并且要解决的问题,笔者就分享下解决这种问题的思路、具体的解决方案以及优雅的解决思路。
一、解决方案介绍
目前业界数据隔离方案
1、独立数据库,通过动态切换数据源来实现多租户
2、共享数据库,隔离数据架构
3、共享数据库,共享数据表,使用字段来区分不同租户,此方案成本最低
以上方案从上到下,安全性逐渐降低。由于考虑到安全问题,故采用第一种方案解决数据隔离
优点:
- 非常安全
- 数据互不影响,性能互不影响
- 数据迁移,数据扩展方便
缺点:
- 需要维护大量的数据库
- 需要自行切换数据库,开发量多且实现复杂
具体技术实现
简单的架构图
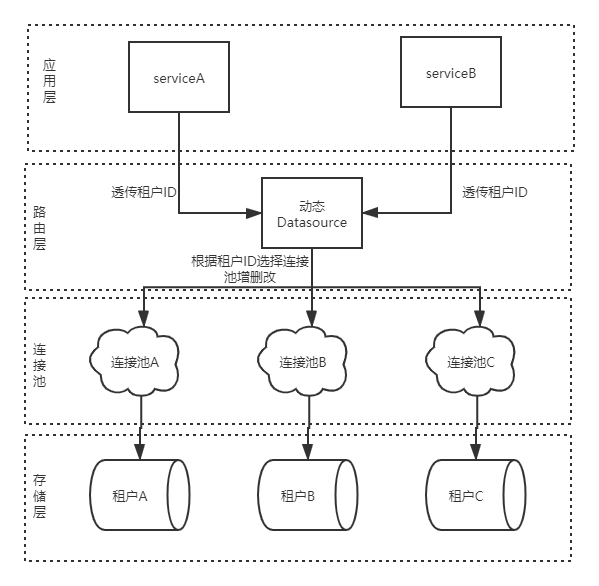
如图所示,SaaS项目大概架构图,关键点是应用层传参,以及路由层的实现。
实现
1、应用层:项目中应用service层是dubbo服务,而且项目分多层,这里需要考虑到多层服务场景下,如何优雅传参问题,如下图所示
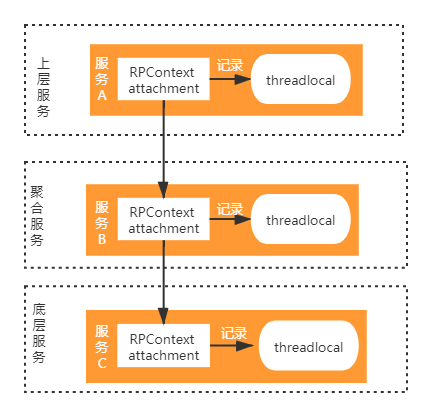
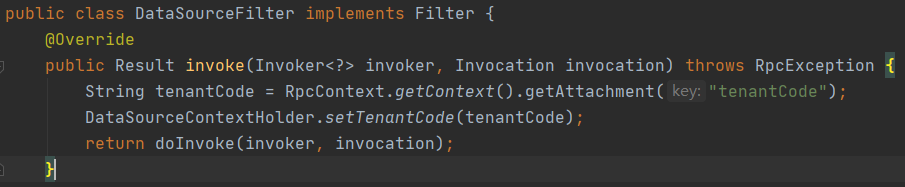
我们考虑到租户ID是唯一标识,和业务参数绑定在一起不优雅,所以两种参数分开处理,业务参数直接参数透传,租户ID唯一标识通过隐式传参来处理(参考dubbo http://dubbo.apache.org/zh-cn/docs/user/demos/attachment.html),并且参数记录到服务本地的threadlocal中,以便后续其他业务需要。具体实现如下:
2、路由层:路由层实现主要是自行实现spring框架中DataSource接口,自定义dynamicDataSource类,然后implement DataSource接口,实现getConnection方法。然后重新定义SqlSessionFactory的bean,将自定义DataSource类属性注入。

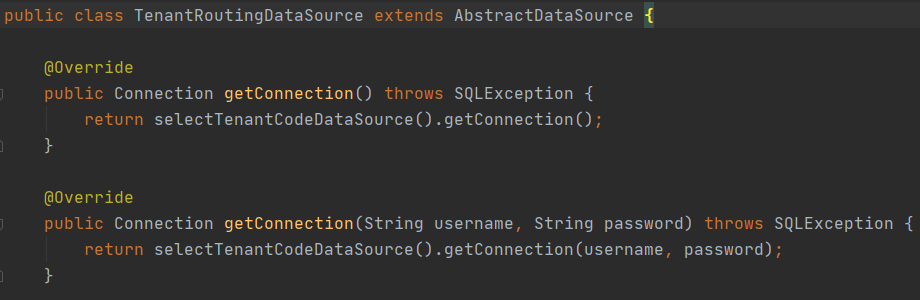
然后我们只需要关注getConnection方法根据租户ID,选择相对应的租户连接池就可以了。
如图中,我们只需要实现这个selectTenantCodeDataSource()这个方法就可以了,这个方法实现很简单,这里就不贴图了。selectTenantCodeDataSource()方法主要就是从threadlocal中拿租户ID,然后去缓存池map中拿出连接池信息。

其中,dataSourceCachePool是在初始化配置时候,将所有的租户连接池直接创建,然后扔到dataSourceCachePool。key是租户的ID,value是连接池信息。
具体的初始化配置:
/**
* 初始化数据源
*/
@Configuration
public class DataSourceInit {
@PostConstruct
public void InitDataSource() {
log.info("=====初始化数据源=====");
TenantRoutingDataSource tenantRoutingDataSource = (TenantRoutingDataSource)ApplicationContextProvider.getBean("tenantRoutingDataSource");
Map<String, DataSourceCache> dataSourceCachePool = new HashMap<>();
List<TenantInfo> tenantList = tenantInfoService.InitTenantInfo();
for (TenantInfo tenantInfo : tenantList) {
log.info(tenantInfo.toString());
HikariDataSource dataSource = new HikariDataSource();
dataSource.setDriverClassName(tenantInfo.getDatasourceDriver());
dataSource.setJdbcUrl(tenantInfo.getDatasourceUrl());
dataSource.setUsername(tenantInfo.getDatasourceUsername());
dataSource.setPassword(tenantInfo.getDatasourcePassword());
dataSource.setDataSourceProperties(master.getDataSourceProperties());
dataSourceCachePool.put(tenantInfo.getTenantId(), dataSource);
}
//设置数据源
tenantRoutingDataSource.setDataSources(dataSourceCachePool);
}
}
二、方案的隐藏缺点以及解决
隐藏的缺陷
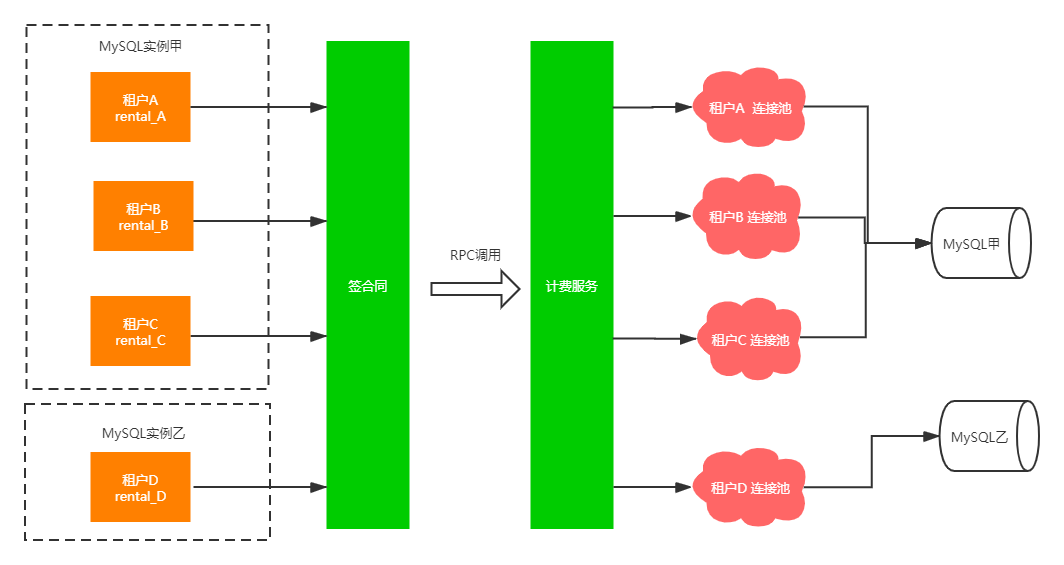
相信有一定开发经验的读者应该能想到,上述方案最大的缺点就是性能问题,对MySQL有非常大的影响。因为一开始初始化非常多的连接池,就会占用连接资源,比如租户从100个扩展到了1000个以及更多,那么连接池数量就线性增长,如果一个连接池保持15个活跃连接的话,那么连接数就是15*1000,此时如果MySQL的maxconntion的数量非常小,那么MySQL侧就会抛出”too many connctions“错误,在应用层方面就是MySQL不可用了。
没优化之前的架构:
解决
想保持数据库分离,又要考虑到MySQL性能问题,只能向连接池优化的方向去考虑,其实可以减少数量就可以了,这里实现方案就是一个数据库实例一个连接池,如下图所示:
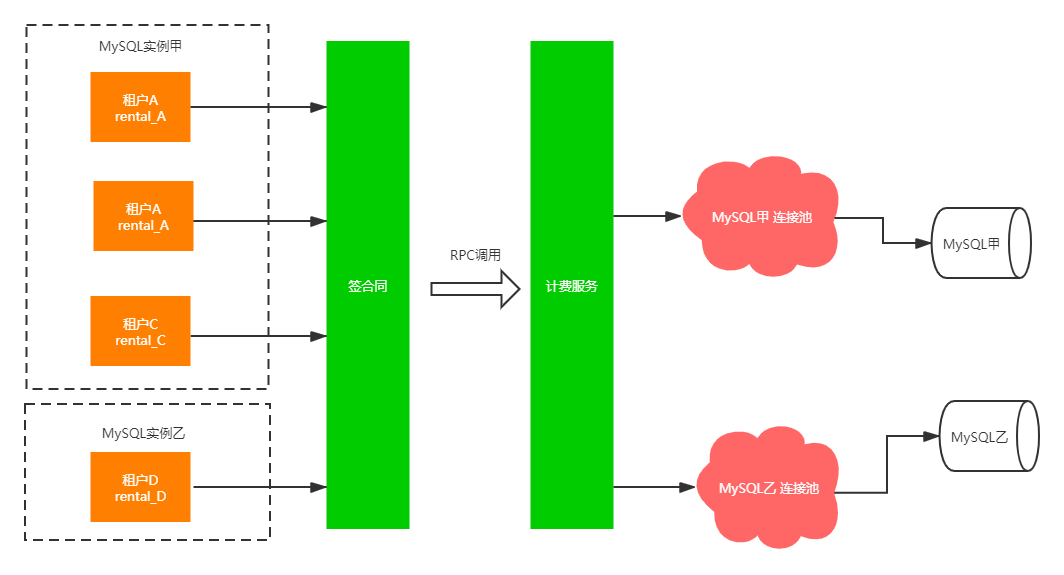
具体实现就是将上述方案中的dataSourceCachePool的key改为 “IP+端口”,作为key。然后再数据源路由层,多一层映射(租户ID——>数据库实例)就可以了。
三、更优雅方案解决企业内部开发痛点
现状
现状:企业内部项目组开发数据源路由,各个人员开发水平不一,各种路由方案实现不同,自己组内的开发的方案只能自己组内使用,并且实现复杂,耗人力物力。
目标:项目组使用直接引入maven包,任何配置都不要配置(自定义的话需要自行在自己项目中配置属性),开箱即用。
具体实现
原理:直接采用springboot starter开发,将上述方案所有的逻辑和技术实现单独放入springboot starter工程中,采用外部配置的方式实现自定义配置。
开发者实现:网上有许多springboot starter开发的流程和开发案例,笔者这里就只贴出关键的代码
1、自动装配类:spring.factories中写入这个类DataSourceAutoConfigure,实现bean的自动装入,类里面主要是实现SqlSessionFactory和PlatformTransactionManager,然后在TenantRoutingDataSource的getconnection方法中自定义实现路由逻辑。
@Configuration
public class DataSourceAutoConfigure {
@Resource
private TenantRoutingDataSource tenantRoutingDataSource;
@Bean
@ConditionalOnMissingBean(SqlSessionFactory.class)
@ConditionalOnBean(TenantRoutingDataSource.class)
public SqlSessionFactory sqlSessionFactory() throws Exception{
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(tenantRoutingDataSource);
Objects.requireNonNull(sqlSessionFactoryBean.getObject()).getConfiguration().setMapUnderscoreToCamelCase(true);
return sqlSessionFactoryBean.getObject();
}
@Bean
@ConditionalOnMissingBean(PlatformTransactionManager.class)
@ConditionalOnBean(TenantRoutingDataSource.class)
public PlatformTransactionManager platformTransactionManager() {
return new DataSourceTransactionManager(tenantRoutingDataSource);
}
}
2、Java SPI机制:利用Javaspi 来获取用户自定义的mybatis plugin。这样做的好处是,不用每次增加一个plugin,就改动数据路由组件的代码。
public SqlSessionFactory sqlSessionFactory(@Qualifier("tenantRoutingDataSource") TenantRoutingDataSource tenantRoutingDataSource) throws Exception{
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(tenantRoutingDataSource);
Interceptor[] plugins = loadMybatisPlugin();
if(plugins.length > 0){
sqlSessionFactoryBean.setPlugins(plugins);
}
Objects.requireNonNull(sqlSessionFactoryBean.getObject()).getConfiguration().setMapUnderscoreToCamelCase(true);
return sqlSessionFactoryBean.getObject();
}
// SPI机制获取插件
private Interceptor[] loadMybatisPlugin(){
List<Interceptor> interceptors = new ArrayList<>();
ServiceLoader<Interceptor> load = ServiceLoader.load(Interceptor.class);
load.forEach(interceptors::add);
return interceptors.toArray(new Interceptor[0]);
}
}
3、dubbo filter扩展接口:获取租户ID,并且需要加@Activate注解,这样dubbo在初始化filter链的时候,自动将这个filter注册到filter链中,这样做的好处就是,用户在自己工程中不需要配置filter这个参数,无需增加任何的配置。
@Activate(group = {"provider"})
public class TenantCodeContextFilter implements Filter {
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
String tenantCode = RpcContext.getContext().getAttachment("tenantCode");
TenantCodeContextHolder.setTenantCode(tenantCode);
return invoker.invoke(invocation);
}
}
4、检查用户侧自定义配置是否正确:检查用户的配置是否合理,不合理的话再容器就绪阶段就会抛出异常
@Component
public class CheckConfigListener implements ApplicationListener<ApplicationReadyEvent> {
@Override
public void onApplicationEvent(ApplicationReadyEvent applicationReadyEvent) {
ConfigurableApplicationContext applicationContext = applicationReadyEvent.getApplicationContext();
ConfigurableEnvironment environment = applicationContext.getEnvironment();
// 检查用户自定义配置是否正确,自行实现
checkDatasourceConfig(environment);
}
}
5、利用缓存池保存多个dataSource对象,一个MySQL实例对应一个dataSource对象,一个dataSource对应多个租户,而不是一个dataSource对应一个租户,这样的好处就是,如果一个MySQL实例里面的租户数据库过多,不会导致一个MySQL实例连接数膨胀问题。
/**
* 数据源缓存池
* Key 一个MySQL数据库连接信息key
* Value 缓存时RDS连接信息与DataSource
*/
private final Map<String, DataSourceCache> dataSourceCachePool = new ConcurrentHashMap<>();
用户使用:直接引入相应的maven,方便快捷
四、TODO后续优化
- 目前多租户数据源通用工程只支持Dubbo的调用,未来可扩展支持多种协议如HTTP、gRPC
- 目前只支持Hikari数据源,后续支持多种数据源类型,比如Durid
- 如果租户数据非常大,可以考虑空间换时间思想,使用缓存存放租户的数据源配置,提升查询效率。
参考
- SaaS系统数据隔离方案——https://blog.arkency.com/comparison-of-approaches-to-multitenancy-in-rails-apps/