幻读原理
1、定义:
幻读指的是一个事务在前后两次查询同一个范围的时候,后一次查询看到了前一次查询没有看到的行
幻读:提交隔离级别下看到的,严格来说不算。因为这个就是读提交隔离级别下“设计内”的问题
对于读提交隔离级别,这个算“feature”,对于可重复读,这个是”bug”, 所以要解决,称呼这个bug为幻读
2、注意:
- 在可重复读隔离级别下,普通的查询是快照读,是不会看到别的事务插入的数据的。因此,幻读在“当前读”下才会出现。
- 幻读只针对新增的行,即使把所有的记录都加上锁,还是阻止不了新插入的记录
- 间隙锁是在可重复读隔离级别下才会生效的。如果把隔离级别设置为读提交的话,就没有间隙锁了。
- 隔离级别为读提交的话,就会出现幻读【严格来说RC级别下不是幻读】情况。并且需要将binlog的模式设置为row模式(binlog三种模式https://www.cnblogs.com/xingyunfashi/p/8431780.html),不能使用statement格式,statement会导致数据一致性问题(没有间隙锁)
为什么要设置为row?
间隙锁是在可重复读隔离级别下才会生效的。所以,你如果把隔离级别设置为读提交的话,就没有间隙锁了。但同时,你要解决可能出现的数据和日志不一致问题,需要把 binlog 格式设置为 row。
- 主键之间也会也有间隙锁,如下图,执行select * from t where id=N for update; 如果没有这行会锁住间隙(5,10)(有一条5和一条10的记录)。如下图,多线程执行语句会导致死锁

3、解决:
间隙锁和行锁,合成为next-key lock,next-key lock是前开后闭区间,单独间隙锁是前开后开区间
4、后果:
间隙锁的引入,可能会导致同样的语句锁住更大的范围,影响并发度
5、案例
案例1、select * from t where d=5 for update,d没有索引
这个时候会扫描全表,会给表记录所有的行加上行锁,还会加上间隙锁。比如表t有6条记录,会上6条行锁,以及7个间隙锁。
结论:对于非索引字段进行update或select .. for update操作,代价极高。所有记录上锁,以及所有间隔的锁。对于索引字段进行上述操作,代价一般。只有索引字段本身和附近的间隔会被加锁。
online DDL 原理
1、MDL锁(表元数据锁)在online DDL的体现?
作用:维护表元数据的数据一致性,保证DDL操作与DML操作之间的一致性。如果在SQL查询期间修改了表结构就会有问题。
总结:MDL作用是防止DDL和DML并发的冲突
2、过程
-
当对一个表做增删改查操作的时候,加 MDL 读锁;当要对表做结构变更操作的时候,加 MDL 写锁。
结论:加读锁则所有线程可正常读元数据,不影响增删改查操作,只是不能修改表结构;加写锁则只有拥有锁的线程可以读写元数据,也就是修改表结构,其它线程不能执行任何操作,包括修改表结构与增删改查。 -
事务中的 MDL 锁,在语句执行开始时申请,但是语句结束后并不会马上释放,而会等到整个事务提交后再释放。
注:一般增删改查语句默认加上MDL读锁
结论:当有未提交的事务时候,或者是长事务时候,如果这个时候进行增删改查,是一个危险的操作,可能阻塞其它增删改查请求,或导致线程爆满。
3、online DDL工作原理
- 拿MDL写锁
- DDL执行准备
- 降级成MDL读锁
- DDL核心执行(耗时最多的)
- 升级成MDL写锁
- DDL最终提交
- 释放MDL锁
注:除了第四步,其他都是获取锁,如果没有冲突,获取锁的时间较小。其中第四步是读锁,所以是可以正常读写数据所以被称为Online DDL。
oderby 工作原理
1、引出
explain 的extra信息里面出现了filesort,MySQL 会给每个线程分配一块内存用于排序,称为 sort_buffer。
sort_buffer_size,就是 MySQL 为排序开辟的内存(sort_buffer)的大小。如果要排序的数据量小于 sort_buffer_size,排序就在内存中完成。但如果排序数据量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。
外部排序一般使用归并排序算法。
2、排序类型
全字段排序和rowID排序
全字段排序:会找出主键索引的所有字段数据放入sort_buffer中排序
缺点:返回的字段很多的话,那么 sort_buffer 里面要放的字段数太多,这样内存里能够同时放下的行数很少,要分成很多个临时文件,排序的性能会很差
rowID排序:要排序的列只有排序字段和ID
缺点:rowid 排序多访问了一次表 t 的主键索引,多了磁盘读
MySQL设计思想:如果内存够,就要多利用内存,尽量减少磁盘访问。
3、增加覆盖索引和联合索引优化排序
索引默认数据是有序的,这样可以避免使用sort_buffer(全字段排序和rowID排序)来进行排序
4、额外案例
1)无条件查询如果只有order by create_time(create_time是索引),那么不会走索引
原因:优化器认为走二级索引再去回表成本比全表扫描排序更高,所以选择走全表扫描,然后利用全字段排序和rowID排序其中一种排序。
select count工作原理
1、count(*) 实现方式
在不同的 MySQL 引擎中,count() 有不同的实现方式。
MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count() 的时候会直接返回这个数,效率很高;
而 InnoDB 引擎就麻烦了,它执行 count(*) 的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。
2、为什么InnoDB 不跟 MyISAM 一样,也把数字存起来呢
因为InnoDB 有MVCC,不同时刻不同事务之间有可能的结果不一样
3、小结一下
MyISAM 表虽然 count() 很快,但是不支持事务;,加了where条件也很慢
show table status 命令虽然返回很快,但是不准确;
InnoDB 表直接 count() 会遍历全表,虽然结果准确,但会导致性能问题
4、count(*)、count(主键 id)、count(字段) 和 count(1) 等不同用法的性能,有哪些差别?
count语义:count() 是一个聚合函数,对于返回的结果集,一行行地判断,如果 count 函数的参数不是 NULL,累计值就加 1,否则不加。最后返回累计值
得出结论:count(*)、count(主键 id) 和 count(1) 都表示返回满足条件的结果集的总行数;而 count(字段),则表示返回满足条件的数据行里面,参数“字段”不为 NULL 的总个数
5、性能对比:
count(主键ID):InnoDB 引擎遍历整张表,但不取值。server 层拿到 id 后,判断是不可能为空的,就按行累加
count(1):InnoDB 引擎遍历整张表,把每一行的ID取出来。server 层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加
count(字段):一行行地从记录里面读出这个字段,判断不能为 null,按行累加
count():count()是个例外,目前MySQL只针对了这个做了优化,并不会把全部字段取出来,而是专门做了优化,不取值。count(*) 肯定不是 null,按行累加。
6、结论
count(字段) < count(主键ID)< count(1)=count()
1、因为count() 和 count(1) 不取字段值,引擎层减少往 server层的数据返回,所以比其他count(字段)要返回值的【性能】较好;
2、为什么count(字段)< count(主键ID),因为如果选择count(ID),那么MySQL会自动选择最小的索引树来遍历,如果是count(字段),而且字段没有索引,那么会使用主键索引。主键索引很大。
普通索引和唯一索引选择
1、普通索引和唯一索引选择
- 查询性能都一样
- 更新分两种情况
- 这个记录要更新的目标页在内存中:
对于唯一索引来说,找到 3 和 5 之间的位置,判断到没有冲突,插入这个值,语句执行结束;
对于普通索引来说,找到 3 和 5 之间的位置,插入这个值,语句执行结束。
总结:目标记录在内存buffer pool中的话,普通索引和唯一索引更新性能是一致的。
2)这个记录要更新的目标页不在内存中:
对于唯一索引来说,需要将数据页读入内存,判断到没有冲突,插入这个值,语句执行结束;
对于普通索引来说,则是将更新记录在 change buffer,语句执行就结束了。
总结:唯一索引将数据页读入内存涉及随机访问IO,操作成本极高。change buffer避免更新磁盘,减少了随机磁盘访问,提供性能。
案例:某个业务的库内存命中率突然从 99% 降低到了 75%,整个系统处于阻塞状态,更新语句全部堵住
原因:业务有大量插入数据的操作,开发人员把其中的某个普通索引改成了唯一索引。
2、changebuffer的使用场景
- 唯一索引的更新就不能使用 change buffer,实际上也只有普通索引可以使用。
- 对于写多读少的业务来说,页面在写完以后马上被访问到的概率比较小,此时 change buffer 的使用效果最好。这种业务模型常见的就是账单类、日志类的系统。
- 如果是写完立马读的场景,建议关闭change buffer ,因为立马查询会访问数据页,会进行merge操作
merge:将 change buffer 中的操作应用到原数据页,得到最新结果的过程称为 merge。除了访问这个数据页会触发 merge 外,系统有后台线程会定期 merge。在数据库正常关闭(shutdown)的过程中,也会执行 merge 操作。
3、change buffer 和 redo log两个分别是如何提高性能的
redo log 主要节省的是随机写磁盘的 IO 消耗(转成顺序写),
对于普通索引的修改,则会记录到change buffer,而 change buffer 主要节省的则是随机读磁盘的 IO 消耗。
4、举个简单的例子来说明 merge,changebuffer,redolog的关系
-
插入(id1,k1) (id2,k2)两条记录,k1 所在的数据页在内存 (InnoDB buffer pool) 中,k2 所在的数据页不在内存中
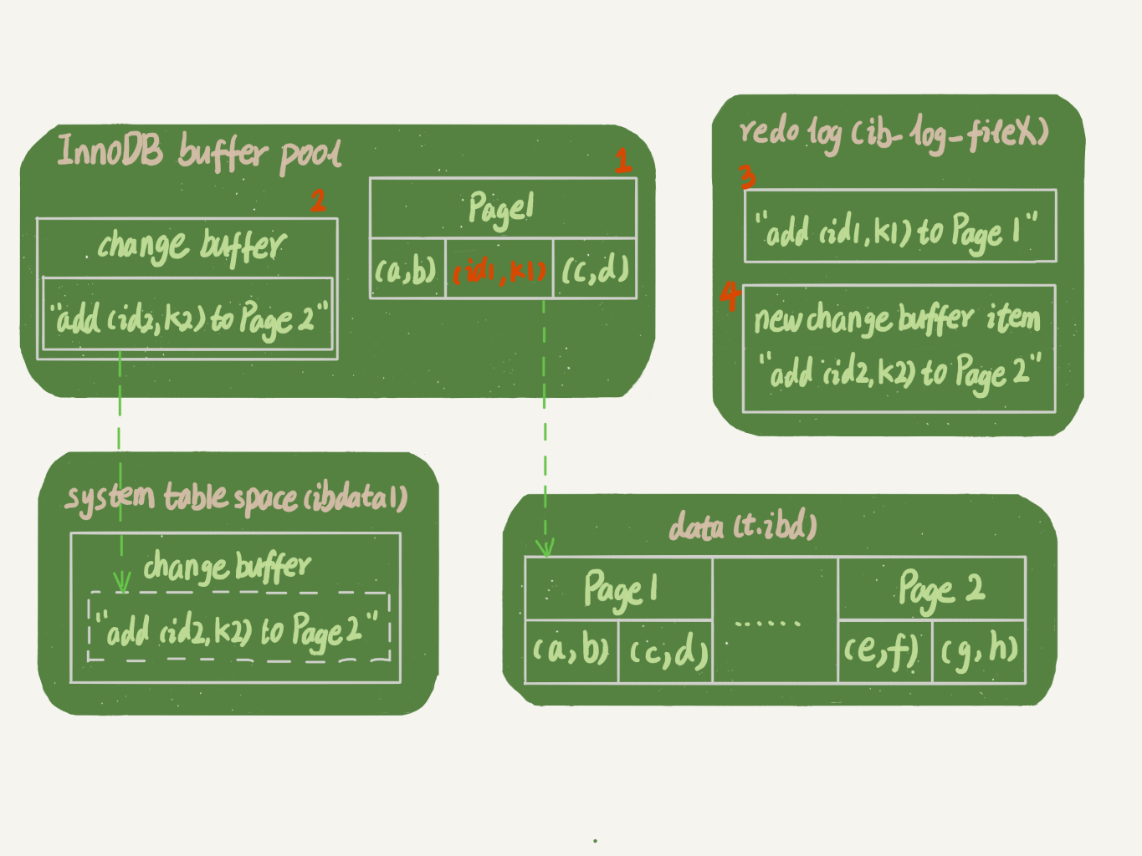
以上操作是:
1)Page 1 在内存中,直接更新内存;
2)Page 2 没有在内存中,就在内存的 change buffer 区域,记录下“我要往 Page 2 插入一行”这个信3)将上述两个动作记入 redo log 中(图中 3 和 4)。 -
执行查询操作select * from t where k in (k1, k2)
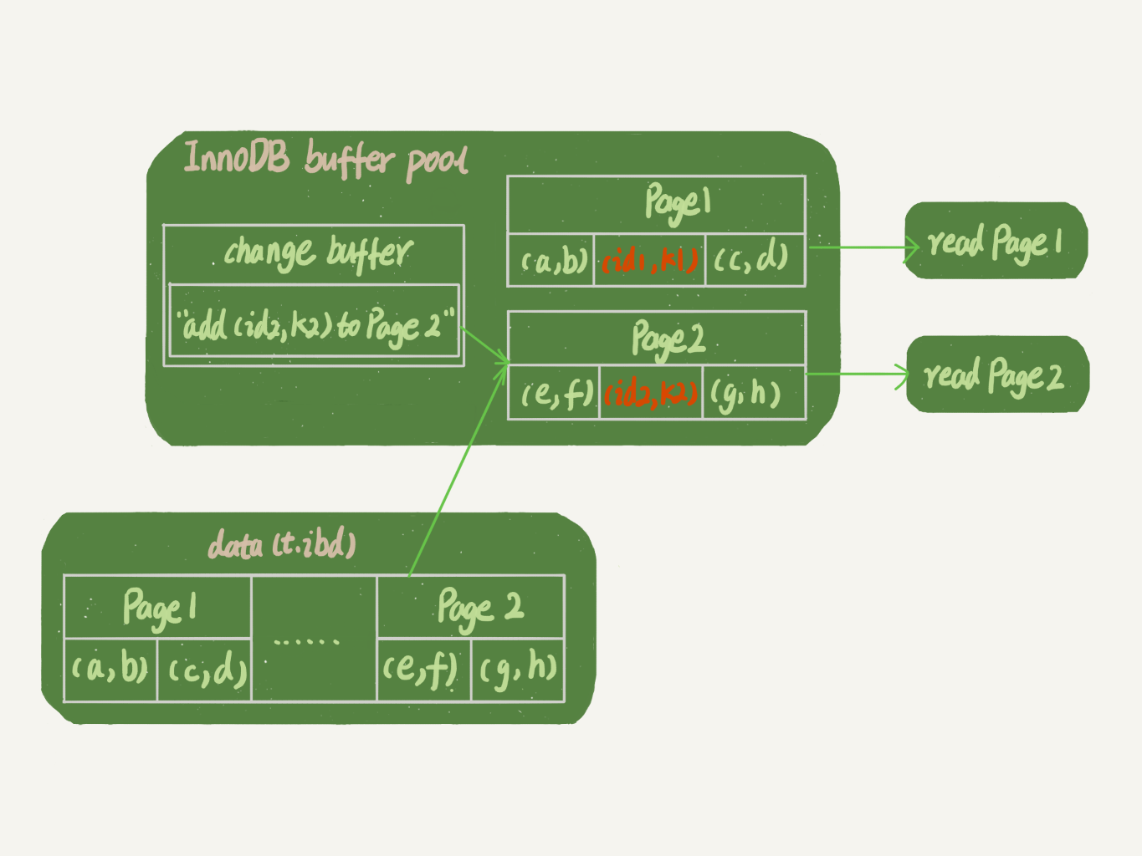
以上操作是:
1)如果k1对应的数据页在buffer pool内存中,那么直接从内存中查出并且返回。这里不用直接从redolog中读盘
2)如果k2对应的数据页不在内存中,那么会读盘,读数据到数据页page2中,然后应用 change buffer 里面的操作日志,做merge操作,并且返回正确的数据
注:
- 此时数据页是脏页,需要刷盘flush
- change buffer虽然是在内存中的,如何避免停电导致的丢失呢?
1).change buffer有一部分在内存有一部分在ibdata.做purge操作,应该就会把change buffer里相应的数据持久化到ibdata
2.)redo log里记录了数据页的修改以及change buffer新写入的信息
MySQL抖动可能原因
1、概念
当内存数据页跟磁盘数据页内容不一致的时候,我们称这个内存页为“脏页”。内存数据写入到磁盘后,内存和磁盘上的数据页的内容就一致了,称为“干净页”。内存里的数据写入磁盘的过程,术语就是 flush
更新操作:其实就是在写内存和日志
MySQL 偶尔“抖”一下的那个瞬间:可能就是在刷脏页
2、触发刷flush时机
- redo log写满
redo log是一个环形的数据结构,当数组redo log写满了,会停止所有的更新操作。checkpoint 往前推进,redo log 留出空间可以继续写。
checkpoint 如果要往前移动,就需要将两个点之间的日志(浅绿色部分),对应的所有脏页都 flush 到磁盘上。
这种对数据库影响是很严重的,会停止所有的更新操作
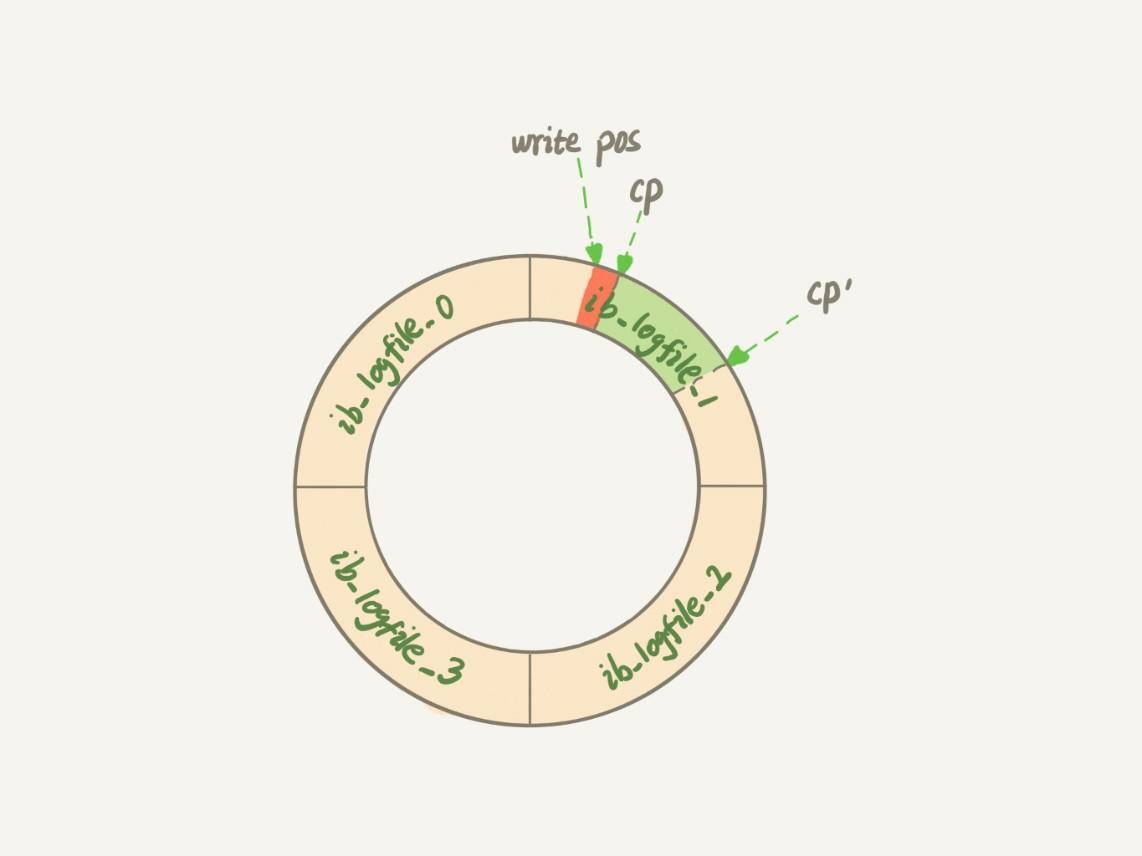
-
BufferPool内存池无可用内存,需要淘汰脏页,淘汰脏页需要flush
当需要新的内存页,而内存不够用的时候,就要淘汰一些数据页,空出内存给别的数据页使用。这时候只能把最久不使用的数据页从内存中淘汰掉:。如果淘汰的是“脏页”,就要先将脏页写到磁盘。 -
MySQL空闲会主动flush
-
MySQL 正常关闭的情况。
这时候,MySQL 会把内存的脏页都 flush 到磁盘上,下次 MySQL 启动的时候,就可以直接从磁盘上读数据,启动速度会很快。
3、Innodb刷脏页的策略
正确地告诉 InnoDB 所在主机的 IO 能力,通过innodb_io_capacity参数让InnoDB知道磁盘IO能力,以便其正确地刷脏页。
建议:innodb_io_capacity设置为磁盘的 IOPS。 磁盘的 IOPS,也就是在一秒内,磁盘进行多少次 I/O 读写,是衡量磁盘性能的主要指标。
刷脏页慢可能导致的情况:内存脏页太多,其次是 redo log 写满。
总结: 无论是你的查询语句在需要内存的时候可能要求淘汰一个脏页,还是由于刷脏页的逻辑会占用 IO 资源并可能影响到了你的更新语句,都可能是造成你从业务端感知到 MySQL“抖”了一下的原因。
4、具体业务场景
出现这样的场景:MySQL的TPS会很低,但是主机的IO压力不大
如果是固态硬盘,那么它的IO读写能力会很大。这个时候如果innodb_io_capacity设置太低,MySQL认为磁盘io能力太差,导致全力刷脏页变慢、脏页累积下来,后续只要刷脏页,不管是内存不够还是日志满了导致的刷脏页,都会导致变慢。
5 Q&A
1、“内存不够用了,要先将脏页写到磁盘“redo log对应的空间会释放嘛?“redo log 写满了,要 flush 脏页”对应的内存页会释放嘛?
redolog 的空间是循环使用的,无所谓释放。 对应的内存页会变成干净页。但是等淘汰的时候才会逐出内存
2、redo log是怎么记录对应脏页是否已经flush了?如果断电了重启导致内存丢失,前面几章说通过redo log进行数据恢复那redo log又怎么去释放空间?
不用记,重启了就从checkpoint 的位置往后扫。 如果已经之前刷过盘的, 不会重复应用redo log
3、redolog是记录的什么?
redolog 记录的是动作,不是结果。Redo log记录的是页的偏移量。比如update语句更新+9,Redo log里是记的+9
4:怎么让MySQL不抖?
设置合理参数配配置,尤其是设置 好innodb_io_capacity 的值,并且平时要多关注脏页比例,不要让它经常接近 75%
5:WAL怎么把随机写转化为顺序写的?
写redolog是顺序写的,先写redolog等合适的时候再写磁盘,间接的将随机写变成了顺序写,性能确实会提高不少